
Large data sets are often awash with data that is difficult to decipher. One may think of textual data, names, unique identifiers, and other sorts of codes. Frequently, people analyzing these datasets are quick to discard these variables. However, sometimes there might be valuable information in this type of data, which might help you with your analysis.
Gladly, R offers the amazing package “stringr,” which is perfect for these purposes. This quick tutorial will show you how you can extract minute but still insightful data from these kinds of variables. In this case, we will be extracting this kind of data from the Titanic dataset.
Loading the Dataset
# install package
install.packages("titanic")
# load package
library(titanic)
### load dataset
df = titanic_train #load datasetInstalling and Loading Stringr
Before we begin, we need to install and load the Stringr package.
# install package
install.packages("stringr")
# load package
library(stringr)Now, we’re all set, and we can begin.
Extracting Titles from Names
As a first exercise, I’d like to extract the titles from the names. This is because I believe, e.g., the nobility is more likely to survive than mere mortals. Also, I hypothesize that young unmarried women (“Miss”) are more likely to survive. Possibly, there might be a lot of information in the title.
To avoid any mistakes, we are first going to run a command that converts all these strings to lowercase and saves them as new variables:
name <- str_to_lower(titanic_train$Name)The title — Mrs in the example above— is preceded by a whitespace and is preceded by a dot. We can use regex (Regular Expression) as a language to communicate this pattern to Stringr and ask it to look for the title in the following way:
(?<=\\s)[[:alpha:]]+(?=\\.)
This pattern consists of three parts:
- (?<=\\s) tells Stringr that the piece of text we are looking for is preceded (?<=) by a whitespace (\\s).
- [[:alpha:]]+ tells Stringr that the piece of text we are looking for consists of one or more (+) letters ([[:alpha:]]).
- (?=\\.) tells Stringr that the piece of text we are looking for is proceeded (?=) by a dot (\\.).
You can see that regex uses all kinds of symbols to communicate patterns. The Stringr Cheat Sheet is a helpful guide for when you want to develop your own patterns.
We extract the title and save it as a new variable by asking Stringr to look for this pattern in the lowercase “Name” strings.
title = str_extract( df$lcName, "(?<=\\s)[[:alpha:]]+(?=\\.)" )
Let’s Plot
Now let’s plot our new variable “title” using plotly and the commands below.
library(dplyr)
library(plotly)
dd <- data.frame(table(title))
# to arrange them in decreasing order
dd$title <- factor(dd$title, levels = unique(dd$title)[order(dd$Freq, decreasing =
TRUE)])
# plotting the barplot
plot_ly(dd, x= ~dd$title,y= ~dd$Freq,type="bar") %>%
layout(xaxis=list(title="title"),yaxis=list(title="count"),
title="Count of Titles")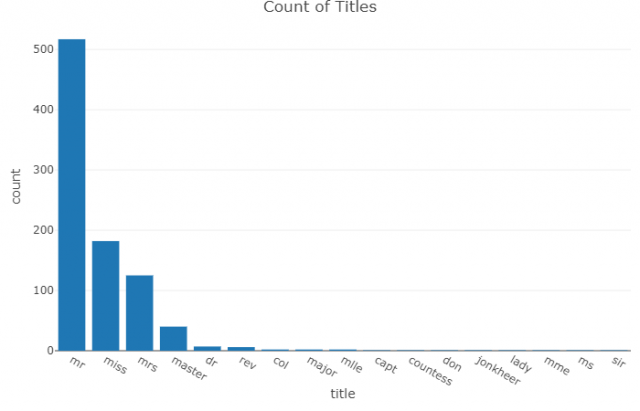
Conclusion
Hence, we saw what is stringr package in R, how we can install and load stringr package in R, how to use it for text mining and creating plots based on the result of stringr package.
This brings the end of this Blog. We really appreciate your time.
Hope you liked it.
Do visit our page www.zigya.com/blog for more informative blogs on Data Science
Keep Reading! Cheers!
Zigya Academy
BEING RELEVANT